import os import random import base64 import time from PIL import Image, ImageDraw, ImageFont, ImageFilter import io from secret import flag import hashlib def pow(hard_level = 6): if hard_level >= 30: hard_level = 30 m = hex(random.getrandbits(16 * 8))[2:] c = hashlib.md5(m.encode()).hexdigest() part = m[:32 - hard_level] print(f'plaintext: {part}' + '?' * hard_level) print(f'md5_hex -> {c}') return part, c def crack(part, c, level = 6): s = int(part, 16) << (level * 4) _limit = s + (1 << level * 4) while s <= _limit: s += 1 seed = hex(s)[2:].encode() if hashlib.md5(seed).hexdigest() == c: return seed def getData(nums = 400): data = [] result = [0 for _ in range(26)] for i in range(nums): c = random.randint(0, 25) data.append(c) result[c] += 1 result = [str(i) for i in result] return data, result def makeImage(data = [], size = 20): img = Image.new('RGB', (size * 50, size * 50)) for y in range(size): for x in range(size): img.paste(pngs[data[x + y * size]], (x * 50, y * 50)) content = io.BytesIO() img.save(content, 'png') img.save('flag.png') img.close() return content.getvalue() def game(): print("Easy pow:") pm, c = pow() m = input("What's is plaintext?\n> ") if hashlib.md5(m.encode()).hexdigest() != c: print('Failed') return data, result = getData() png = makeImage(data) print('now, you get a png: ') print(base64.b64encode(png).decode()) print("##The end, please tell me your list:") _start = time.time() _input = input('> ').split(',') _end = time.time() if _end - _start > 10: print('timeouted') return if _input == result: print("Got it!") print(flag) else: print('Sorry, try again.') if __name__ == '__main__': print('loading pngs, please waiting...') pngs = [] seed = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' for i in range(26): pngs.append(Image.open(f'/app/src/{seed[i]}.png').resize((50, 50), Image.ANTIALIAS)) game()
from PIL import Image from pwn import * import base64 from itertools import product p = remote('47.97.127.1',22398) def getm(c,hash): table = string.hexdigits[:-6] for i in product(table,repeat=6): a = c + ''.join(i) if hashlib.md5(a.encode()).hexdigest() == hash: return a def step1(): p.recvuntil('plaintext:') m = p.recv().decode().split('\n') m1 = m[0].strip().split('?')[0] m2 = m[1].split('->')[1].strip() a = getm(m1,m2) print(a) #p.recvuntil("What's is plaintext") p.sendline(a) p.recvuntil('now, you get a png:') content = '' c = p.recv().decode() while "##The end" not in c: content += c c = p.recv().decode() content += c content = content.split('##')[0].strip() return content def getdata(): content = step1() print(content) open('new.png','wb').write(base64.b64decode(content)) img = Image.open('new.png') w,h = img.size n = 0 for y in range(0,1000,50): for x in range(0,1000,50): n += 1 a = img.crop((x,y,50+x,50+y)) a.save(f"img/{n}.png") def getflag(): getdata() result = [0]*26 datas = [0]*26 for i in range(26): name = str(i).zfill(2) data = list(Image.open(f'zimubiao/{name}.png').getdata()) datas[i] = data for i in range(1,401): data = list(Image.open(f'img/{i}.png').getdata()) print(datas.index(data),f'{i}.png') result[datas.index(data)] += 1 flag = '' for i in result: flag += str(i)+"," flag = flag[:-1] print(flag) p.sendline(flag) while 1: print(p.recv()) getflag() def getimage(): ls = [] a = {} for i in range(1,401): img = Image.open(f"img/{i}.png") data = list(img.getdata()) a[i] = data for i in a.values(): if i not in ls: ls.append(i) print(len(ls)) for k in ls: for i in a.keys(): if a[i] == k: print(f'img/{i}.png') image = Image.open(f'img/{i}.png') image.save(f'zimubiao/{i}.png') break
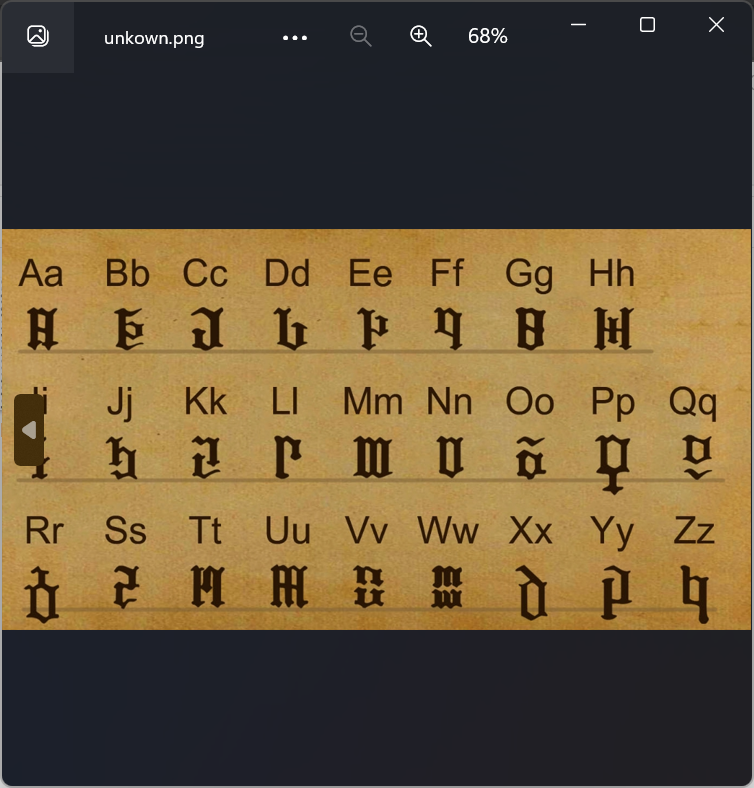
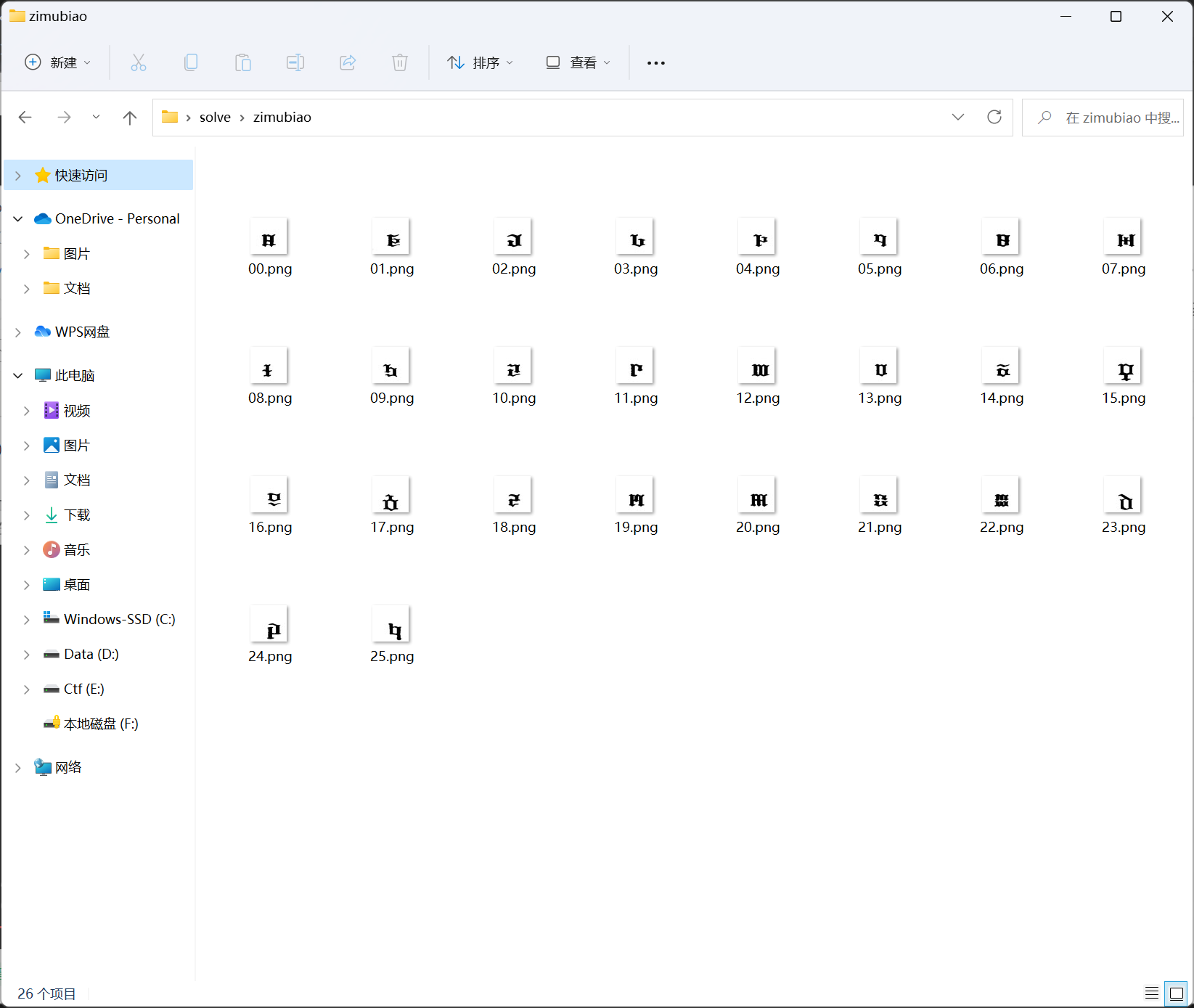
脚本的getimage()是将大图中不重样的小图保存到本地,图片的名称是我自己根据字母表改名的:
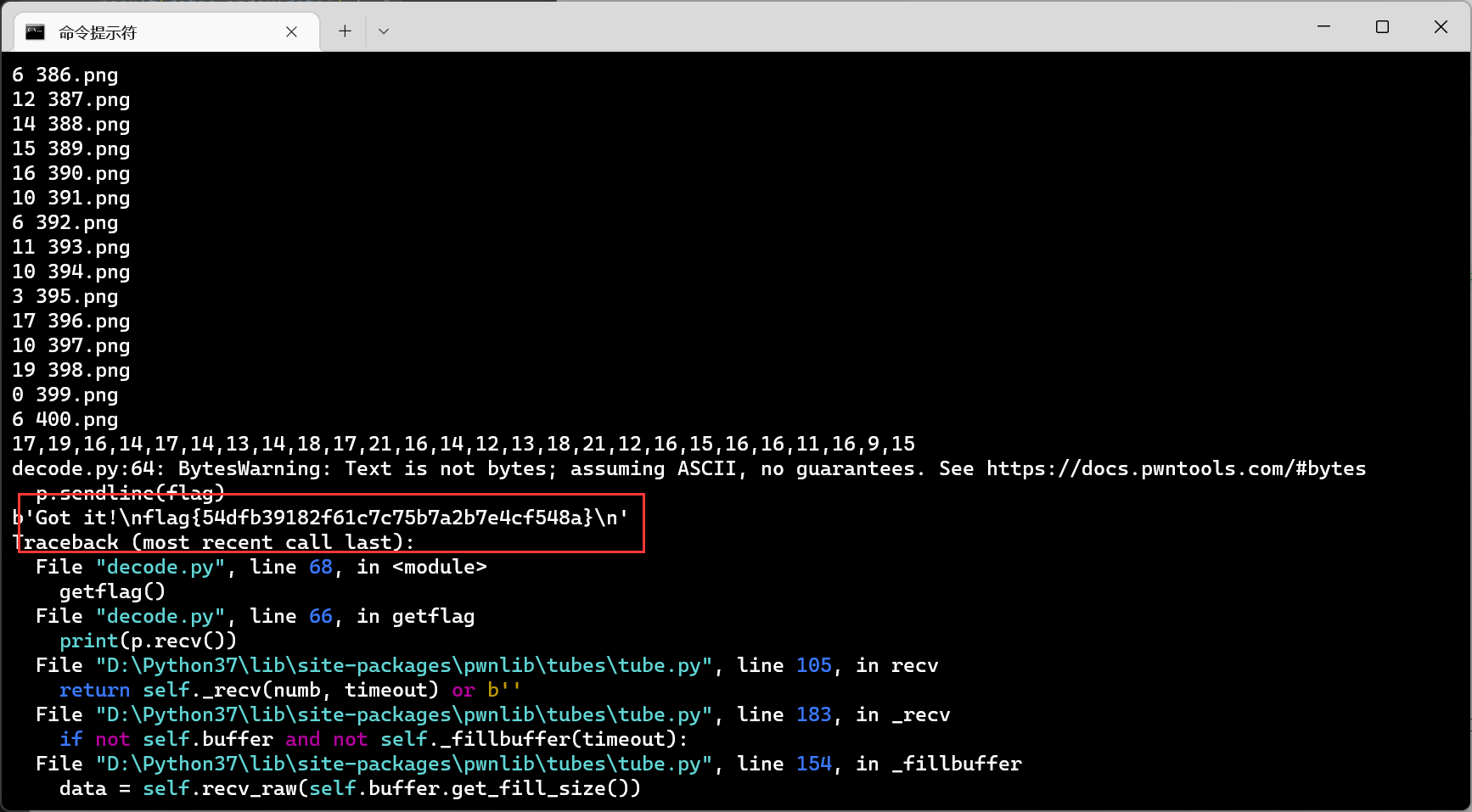
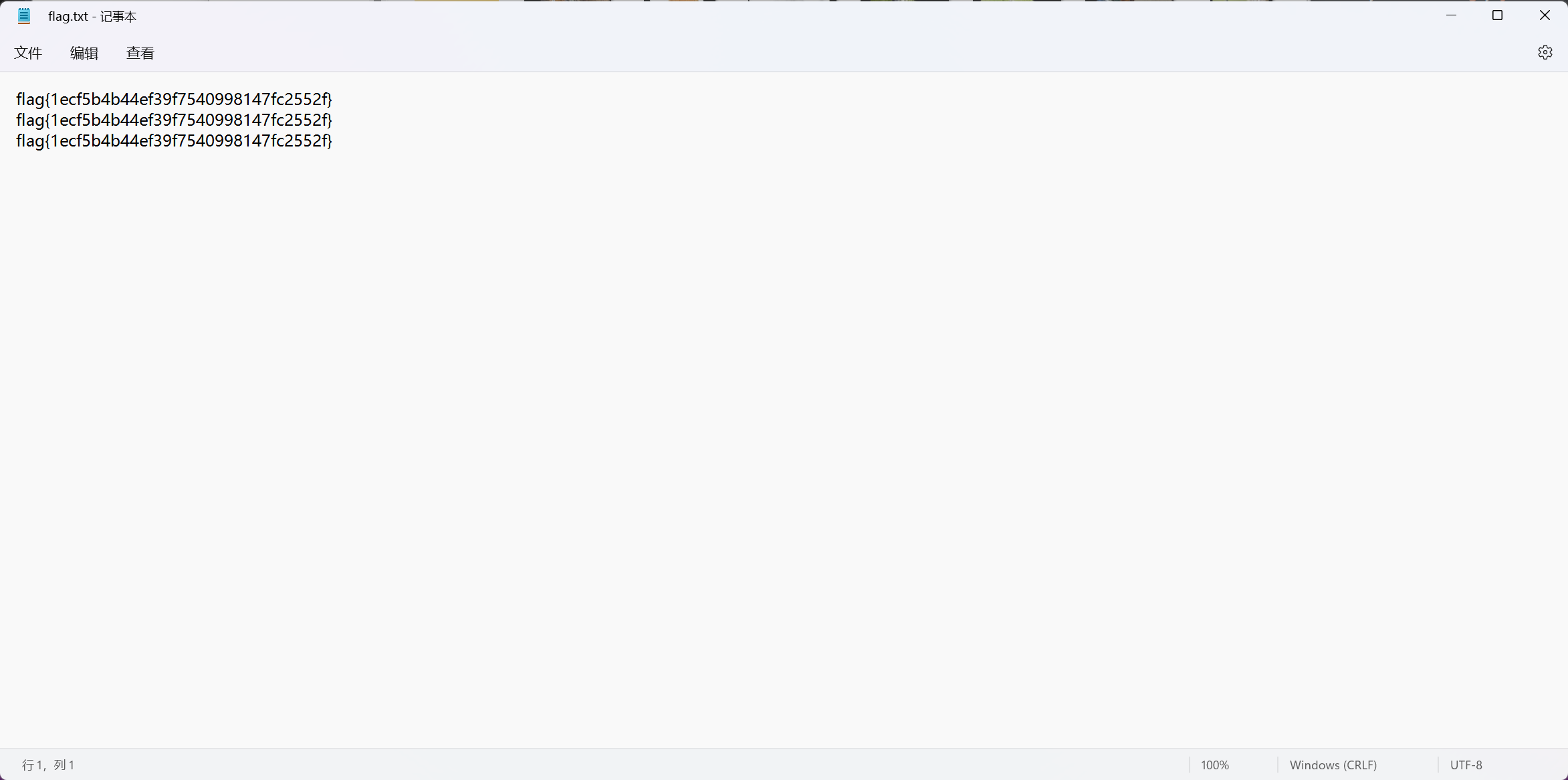
运行得到flag
图片识别
下载附件得到题目源码
import os import random import base64 import time from PIL import Image, ImageDraw, ImageFont, ImageFilter import io from secret import flag import hashlib animals = ['cat', 'pig', 'tigger', 'dog', 'cattle', 'mouse', 'bird', 'chicken', 'rabbit', 'koala', 'horse', 'deer', 'lion', 'elephant'] names = ['1.jpg','10.jpg','2.jpg','3.jpg','4.jpg','5.jpg','6.jpg','7.jpg','8.jpg','9.jpg'] def pow(hard_level = 6): if hard_level >= 30: hard_level = 30 m = hex(random.getrandbits(16 * 8))[2:] c = hashlib.md5(m.encode()).hexdigest() part = m[:32 - hard_level] print(f'plaintext: {part}' + '?' * hard_level) print(f'md5_hex -> {c}') return part, c def crack(part, c, level = 6): s = int(part, 16) << (level * 4) _limit = s + (1 << level * 4) while s <= _limit: s += 1 seed = hex(s)[2:].encode() if hashlib.md5(seed).hexdigest() == c: return seed def game(): print("Easy pow:") pm, c = pow() m = input("What's is plaintext?\n> ") if hashlib.md5(m.encode()).hexdigest() != c: print('Failed') return _score = 0 for _ in range(10): animal = random.choice(animals) name = random.choice(names) img = Image.open(f'/app/animal/{animal}/{name}') img = img.rotate(random.randint(30, 170), expand = 1) x, y = img.size _rate = random.randint(-50, 10) x, y = int(x + x * _rate / 100), int(y + y * _rate / 100) img = img.resize((x, y), Image.ANTIALIAS) content = io.BytesIO() img.save(content, format='jpeg') print(base64.b64encode(content.getvalue()).decode()) img.close() content.close() time.sleep(1) _start = time.time() _input = input("What's animal in this picture?\n> ") _end = time.time() if _end - _start > 3: print('timeouted') return if _input != animal: print(f"Oh, This is {animal}") else: print("Yes, it's") _score += 1 if _score >= 8: print("Great, you are good.") print(flag) else: print('Failed') if __name__ == '__main__': game()
from torchvision.models import resnet50, ResNet50_Weights from PIL import Image from pwn import * import base64 from itertools import product animals = ['cat', 'pig', 'tigger', 'dog', 'cattle', 'mouse', 'bird', 'chicken', 'rabbit', 'koala', 'horse', 'deer', 'lion', 'elephant'] dc = {'tiger':'tigger','brambling':'bird','hamster':'mouse',"Angora":"rabbit","rhinoceros beetle":"horse","koala":"koala","Ibizan hound":"cattle","tabby":"cat","dhole":"deer",'kuvasz':'dog','jacamar':"bird", 'redbone':'horse','Border collie':'dog','Norfolk terrier':'mouse',"muzzle":"elephant","hog":"pig","fox squirrel":'cat','Sussex spaniel':'dog','clumber':'chicken','patas':"deer"} def getm(): p.recvuntil('plaintext:') m = p.recv().decode().split('\n') c = m[0].strip().split('?')[0] hash = m[1].split('->')[1].strip() table = string.hexdigits[:-6] for i in product(table,repeat=6): a = c + ''.join(i) if hashlib.md5(a.encode()).hexdigest() == hash: return a def decode(name): t1 = time.time() content = '' c = p.recvline().decode() print(c) n = 0 while "What's animal in this picture" not in c: content += c c = p.recvline().decode() n += 1 print(n,c[:60]) if "flag" in c: open('flag.txt','a').write(c) content = content.strip().split('\n')[-1] f = open(name,'wb') f.write(base64.b64decode(content)) t2 = time.time() print(f'{name} 图片构写完毕 耗时 {t2-t1}s') def divide(img): # Step 1: Initialize model with the best available weights weights = ResNet50_Weights.DEFAULT model = resnet50(weights=weights) model.eval() # Step 2: Initialize the inference transforms preprocess = weights.transforms() # Step 3: Apply inference preprocessing transforms batch = preprocess(img).unsqueeze(0) # Step 4: Use the model and print the predicted category prediction = model(batch).squeeze(0).softmax(0) class_id = prediction.argmax().item() category_name = weights.meta["categories"][class_id] return category_name def sickimg(): res = getm() p.sendline(res) for i in range(11): t1 = time.time() decode(f"{i}.jpeg") img = Image.open(f"{i}.jpeg") category_name = divide(img) print('模型结果:%s'%category_name) a = 0 if category_name in dc.keys(): for i in dc.keys(): if category_name == i: a = 1 print(f'1 发送{dc[i]}') p.sendline(dc[i]) break else: for i in animals: if i in category_name: print(f'2 发送{i}') a = 1 p.sendline(i) break if a != 1: print(f'3 发送mouse') p.sendline('mouse') t2 = time.time() print("time",t2-t1) for i in range(1000): p = remote('47.97.127.1',29335) try: sickimg() p.close() except: pass sleep(3)
垃圾邮件分析
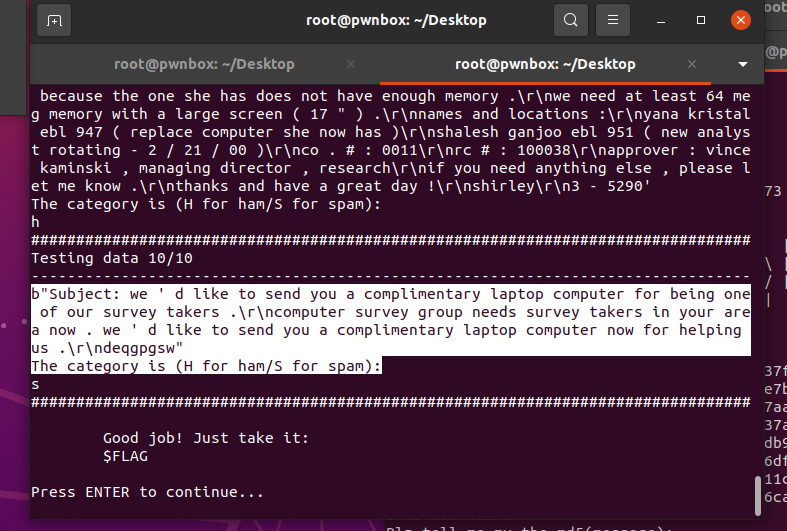
这道题没有附件,直接远程连接题目。
爆破sha256,脚本:
import string from itertools import product import hashlib m1 = 'u8tkfHbguwjvbuf5pdYVbhknh9Y9' m2 = 'ca7a86b1d4d914dd78c5f434b173b8ec8d51cfc71ede5ae1be5b47e54e121cf8' table = string.ascii_letters + string.digits print(table) for i in product(table,repeat=4): a = m1 + ''.join(i) if hashlib.sha256(a.encode()).hexdigest() == m2: print(a,''.join(i)) break